|
|
|
[Contents] | [Index] |
Collaborator: D. Belomestny, V. Essaoulova, A. Hutt, P. Mathé, D. Mercurio, H.-J. Mucha, J. Polzehl, M. Reiß, V. Spokoiny
Cooperation with: R. Brüggemann, Ch. Heyn, U. Simon (Institut für Gewässerökologie und Binnenfischerei, Berlin), P. Bühlmann (ETH Zürich, Switzerland), C. Butucea (Université Paris X, France), M.-Y. Cheng (National Taiwan University, Taipeh), A. Daffertshofer (Free University of Amsterdam, The Netherlands), A. Dalalyan (Université Paris VI, France), J. Dolata (Universität Frankfurt am Main), J. Fan (Princeton University, USA), J. Franke (Universität Kaiserslautern), R. Friedrich (Universität Münster), J. Gladilin (Deutsches Krebsforschungszentrum, Heidelberg), H. Goebl, E. Haimerl (Universität Salzburg, Austria), A. Goldenshluger (University of Haifa, Israel), I. Grama (Université de Bretagne-Sud, Vannes, France), J. Horowitz (Northwestern University, Chicago, USA), A. Juditski (Université de Grenoble, France), N. Katkovnik, U. Ruatsalainen (Technical University of Tampere, Finland), Ch. Kaufmann (Humboldt-Universität zu Berlin), K.-R. Müller (Fraunhofer FIRST, Berlin), A. Munk (Universität Göttingen), M. Munk (Max-Planck-Institut f�r Hirnforschung, Frankfurt am Main), S.V. Pereverzev (RICAM, Linz, Austria), P. Qiu (University of Minnesota, USA), H. Riedel (Universität Oldenburg), B. Röhl-Kuhn (Bundesanstalt f�r Materialforschung und -pr�fung (BAM), Berlin), A. Samarov (Massachusetts Institute of Technology, Cambridge, USA), M. Schrauf (DaimlerChrysler, Stuttgart), S. Sperlich (University Carlos III, Madrid, Spain), U. Steinmetz (Max-Planck-Institut f�r Mathematik in den Naturwissenschaften, Leipzig), P. Thiesen (Universität der Bundeswehr, Hamburg), C. Vial (ENSAI, Rennes, France), Y. Xia (National University of Singapore), S. Zwanzig (Uppsala University, Sweden)
Supported by: DFG: Priority Program 1114 ``Mathematische Methoden der Zeitreihenanalyse und digitalen Bildverarbeitung''(Mathematical methods for time series analysis and digital image processing); DFG Research Center MATHEON, project A3
Description:
The project Statistical data analysis focuses on the development, theoretical investigation and application of modern nonparametric statistical methods, designed to model and analyze complex data structures. WIAS has, with main mathematical contributions, obtained authority for this field, including its applications to problems in technology, medicine, and environmental research as well as risk evaluation for financial products.
Methods developed in the institute within this project area can be grouped into the following main classes.
Research on adaptive smoothing methods is driven by challenging problems from imaging and time series analysis. Applications to imaging include reconstruction of 2D and 3D images from Magnetic Resonance Tomography or microscopy, signal detection in functional Magnet Resonance Imaging (fMRI) experiments, or edge recovery from Positron Emission Tomography (PET) data.
The models and procedures proposed and investigated at WIAS are based on three main approaches: pointwise adaptation, originally proposed in [57] for estimation of regression functions with discontinuities and extended to images in [38], propagation-separation or adaptive weights smoothing, proposed in [39] in the context of image denoising, and stagewise aggregation, introduced in [3].
The main idea of the pointwise adaptive approach is to search, in each design point, for the largest acceptable window that does not contradict the assumed local model, and to use the data within this window to obtain local parameter estimates. This allows for estimates with nearly minimal variance under controlled bias.
Stagewise aggregation, see [3],
is defined as a pointwise adaptation scheme based on an ordered
sequence of ``weak'' local likelihood estimates
![]() (x) of the local parameter
(x) of the local parameter ![]() (x)
at a fixed-point x ordered due to decreased variability.
Starting from the most variable and least biased estimate
(x)
at a fixed-point x ordered due to decreased variability.
Starting from the most variable and least biased estimate
![]() (x),
the procedure sequentially defines the new estimate
(x),
the procedure sequentially defines the new estimate
![]() as a convex combination of the next ``weak'' estimate
as a convex combination of the next ``weak'' estimate
![]() (x) and the previously computed estimate
(x) and the previously computed estimate
![]() (x) in
the form
(x) in
the form
The general concept behind the propagation-separation approach, see [43, 44], is structural adaptation. The procedure attempts to recover for each point the largest neighborhood where local homogeneity with respect to a prespecified model is not rejected. This is achieved in an iterative process by extending regions of local homogeneity (propagation) as long as this does not contradict the structural information obtained in previous iteration steps. Points are separated into different regions if their local parameter estimates become significantly different within the iteration process. This class of procedures is derived from adaptive weights smoothing, as introduced in [39, 41, 42], by adding stagewise aggregation as a control step. This allowed to put the procedures from [41, 42] into a unified and slightly simpler concept and to prove theoretical properties for the resulting estimates.
The propagation-separation approach possesses a number of remarkable properties like preservation of edges and contrasts and nearly optimal noise reduction inside large homogeneous regions. It is almost dimension free and applies in high-dimensional situations. Moreover, if the prespecified model is valid globally, both stagewise aggregation and the propagation-separation approach yield the global estimate. Both procedures are rate optimal in the pointwise and global sense.
The propagation-separation approach enables us to handle locally smooth images [43], see Figure 1 for an example, and local constant likelihood estimation for exponential family models [44] in a unified way. The latter allows, e.g., for images containing Poisson counts, binary or halftone images, or images with intensity-dependent gray value distributions. We now expect to have the necessary understanding and tools to extend the approach to locally smooth exponential family models.
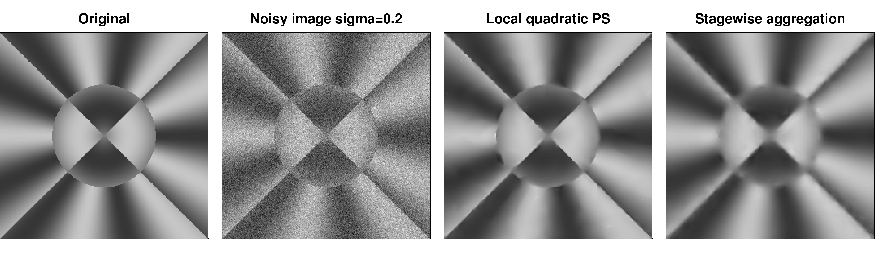 |
Stagewise aggregation turns out to be more suitable for smooth images. It is less sensitive to edges, see again Figure 1, but on the other hand less dependent on the prespecified local model. Due to its less involved structure it allows for much faster implementations and therefore different classes of applications.
In [44], the propagation-separation approach is used to derive a class of classification procedures based on a binary response model. This allows to improve on classical nonparametric procedures like kernel regression and the nearest-neighbor by weakening the problem of optimal parameter choice.
The equivalence of Poisson regression and density estimation allows to extend both the propagation-separation approach and stagewise aggregation to the problem of density estimation. The applicability of the propagation-separation approach from [44] is, being based on a local constant structural assumption, currently restricted to densities with pronounced discontinuities. This limitation will be removed with the extension of the approach to generalized linear models.
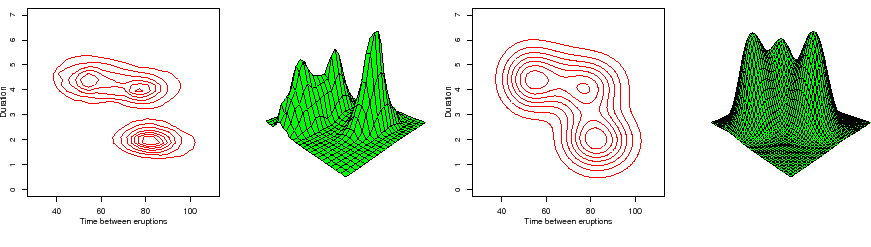
Stagewise aggregation allows for excellent estimates for smooth densities. Figure 2 illustrates the density estimates obtained for the Old Faithful Geyser data set.
 |
A growing number of real-life problems in medicine and biosciences lead to the statistical analysis of large data sets with unknown complex structure. The well-developed statistical theory for traditional parametric models or for uni-(low-)dimensional functional data cannot directly be applied for many of these data sets. We aim to develop novel methods for biomedical signal processing based on neural networks and nonlinear nonstationary time series models. In addition, we tried to combine these methods with microscopic models of biomedical activity to further improve the developed methods. We attack the problem of analysis and modeling of biomedical signals. In one part, the synchronization of multivariate brain signals is investigated by a fixed-point clustering algorithm. It turns out that functional brain processes generate transient signal states, which exhibit global phase synchronization on a dramatically decreased time scale. In a second part, the project aims to model these signal states by neural activity models. Here, we study the spatiotemporal dynamics of neural population activity concerning its stability [1, 18, 19, 20, 22].
Our approach for time series focuses on local stationary time series models. These methods allow for abrupt changes of model parameters in time. Applications for financial time series include volatility modeling, volatility prediction, risk assessment.
ARCH and GARCH models gained a lot of attention and are widely used in financial engineering since they have been introduced in [4, 11]. The simple GARCH(1,1) model is particularly popular suggesting a very natural and tractable model with only three parameters to be estimated. Moreover, this model allows to mimic many important stylized facts of financial time series like volatility clustering (alternating periods of small and large volatility) and persistent autocorrelation (slow decay of the autocovariance function of the absolute or squared returns). The GARCH models are successfully applied to short term forecasting of the volatility and particularly to Value-at-Risk problems, see also the project Applied mathematical finance.
However, it appears that the most crucial problem in the GARCH approach is that GARCH models are not robust w.r.t. violation from the stationarity assumption. If the stationarity assumption is violated, GARCH modeling is essentially reduced to exponential smoothing of the last observed squared returns. [33, 34] also argued that the other stylized facts of financial time series like long-range dependence, persistent autocorrelation, and the integration GARCH effect can be well explained by nonstationarity in the observed data.
Our approach to model local stationary time series is based on the assumption of local homogeneity: For every time point there exists an interval of time homogeneity in which the volatility parameter can be well approximated by a constant. The pointwise adaptive procedure from [32] recovers this interval from the data using local change-point analysis. Then the estimate of the volatility can be simply obtained by local averaging. The performance of the procedure is investigated both theoretically and through Monte Carlo simulations. A comparison with the LAVE procedure from [31] and with a standard GARCH model is provided.
In [45], a general class of GARCH models with time-varying coefficients is introduced. The adaptive weights approach is extended to estimate the GARCH coefficients as a function of time. This is based on a localization of the GARCH model by local perturbation of the likelihood function that allows to test for equivalence of two local models. A simpler semiparametric model in which the nonlinear parameter is fixed is discussed. The performance of the parametric, time-varying non- and semiparametric GARCH(1,1) models and the local constant model from [41] is assessed by means of simulated and real data sets using different forecasting criteria. Our results indicate that the simple local constant model outperforms the other models in almost all cases. The GARCH(1,1) model demonstrates a relatively good forecasting performance as far as the short-term forecasting horizon is considered. However, its application to long-term forecasting seems questionable because of possible misspecification of the model parameters.
In [46], a non-parametric, non-stationary framework for business-cycle dating is developed based on the adaptive weights smoothing techniques from [41, 42]. The methodology is used both for the study of the individual macroeconomic time series relevant to the dating of the business cycle as well as for the estimation of their joint dynamics. Since the business cycle is defined as the common dynamics of some set of macroeconomic indicators, its estimation depends fundamentally on the group of series monitored. Our dating approach is applied to two sets of US economic indicators including the monthly series of industrial production, nonfarm payroll employment, real income, wholesale-retail trade, and gross domestic product (GDP). We find evidence of a change in the methodology of the NBER's Business-Cycle Dating Committee: In the dating of the largest recession, an extended set of five monthly macroeconomic indicators replaced the set of indicators emphasized by the NBER's Business-Cycle Dating Committee in recent decades. This change seems to seriously affect the continuity in the outcome of the dating of business cycles. Had the dating been done on the traditional set of indicators, the last recession would have lasted one year and a half longer. We find that, independent of the set of coincident indicators monitored, the last economic contraction began in November 2000, four months before the date of the NBER's Business-Cycle Dating Committee.
In [55], the authors proposed a new method of analysis of a partially linear model whose nonlinear component is completely unknown. The target of analysis is the indentification of the set of regressors which enter in a nonlinear way in the model function, and the complete estimation of the model including slope coefficients of the linear component and the link function of the nonlinear component. The procedure also allows for selecting the significant regression variables. We also develop a test of linear hypothesis against a partially linear alternative, or, more generally, a test that the nonlinear component is M-dimensional for M = 0, 1, 2,.... The method of analysis goes back to the idea of structural adaptation from [16, 17], where the problem of dimension reduction was considered for a single and multiple index model, respectively. The new approach is very general and fully adaptive to the model structure. The only restrictive assumption is that the dimensionality of the nonlinear component is relatively small. The theoretical results indicate that the procedure provides a prescribed level of the identification error and estimates the linear component with the accuracy of order n-1/2. A numerical study demonstrates a very good performance of the method even for small or moderate sample sizes.
Suppose X1,..., Xn is an i.i.d. sample in a high-dimensional space IRd drawn from an unknown distribution with density f (x). A general multivariate distribution is typically too complex to be recovered from the data, thus dimension reduction methods need to be used to decrease the complexity of the model [2, 8, 54, 56, 60]. Many such dimension reduction techniques rely on some linear representation of data. For instance, PCA projects the data into the orthogonal principal component basis that are defined via the eigenvalue decomposition of the covariance matrix of the vector X. This method is well suited for the case of a normal distribution, because orthogonality implies independence of components for a multivariate Gaussian distribution. However, in practical situations, especially if the assumption of normality is violated, PCA can easily reach its limits.
An alternative approach, the Independent Component Analysis, assumes that the data is a linear transformation of a d-dimensional vector with independent components. Usually these components are assumed to be strictly non-Gaussian except for one Gaussian component to ensure their identifiability [6, 23]. Note that independent components do not necessarily form an orthogonal basis.
In [58], a new approach that allows to bridge these two completely different modeling approaches is developed. The model assumption is that the random vector X can be decomposed into a product of multivariate Gaussian and purely non-Gaussian components leading to the semiparametric class of densities
Ill-posed equations arise frequently in the context of inverse problems, where it is the aim to determine some unknown characteristics of a physical system from data corrupted by measurement errors.
An estimation method based on pointwise recovering of the support function of a planar convex set from noisy observations of its moments is developed in [13]. Intrinsic accuracy limitations in the shape-from-moments estimation problem are shown by establishing a lower bound on the rate of convergence of the mean squared error. The proposed estimator is near-optimal in the sense of the order. [14] considers the problem of recovering edges of an image from noisy Positron Emission Tomography (PET) data. The original image is assumed to have a discontinuity jump (edge) along the boundary of a compact convex set. The Radon transform of the image is observed with noise, and the problem is to estimate the edge. We develop an estimation procedure which is based on recovering the support function of the edge. It is shown that the proposed estimator is nearly optimal in order in a minimax sense. Numerical examples illustrate reasonable practical behavior of the estimation procedure.
For ill-posed problems it is often impossible to get sensible results
unless special methods, such as Tikhonov regularization, are used.
Work in this direction is carried out in collaboration with S.V.
Pereverzev, RICAM Linz. We study linear problems where an operator A
acts injectively and compactly between Hilbert spaces, and the
equation is disturbed by noise. Under a priori smoothness assumptions
on the exact solution x, such problems can be regularized. Within the
present paradigm, smoothness is given in terms of general source
conditions, expressed through the operator A as x =
![]() (A*A)v,| v|
(A*A)v,| v| ![]() R, for some increasing function
R, for some increasing function ![]() ,
,
![]() (0) = 0. This approach allows to treat regularly and severely
ill-posed problems in a unified way.
The study [25] provides a general approach to determine the degree of
ill-posedness for statistical ill-posed problems and thus the
intrinsic complexity for such problems. Moreover,
in [28] the numerical analysis could be extended to statistical
ill-posed problems, including the issue of discretization and
adaptation, when the smoothness of the true solution is not known
a priory.
(0) = 0. This approach allows to treat regularly and severely
ill-posed problems in a unified way.
The study [25] provides a general approach to determine the degree of
ill-posedness for statistical ill-posed problems and thus the
intrinsic complexity for such problems. Moreover,
in [28] the numerical analysis could be extended to statistical
ill-posed problems, including the issue of discretization and
adaptation, when the smoothness of the true solution is not known
a priory.
Adaptive parameter choice strategies date back to the original paper by Phillips [30] and it became an important issue how this can be given a sound mathematical basis. Based on new tools for variable Hilbert scales, as developed in [27], the discrepancy principle is thoroughly analyzed in [26] while in [29], its extension to discretization was considered. The analysis results in a new algorithm, which allows to take into account the advantages of the discrepancy principle while classical projection methods do not.
Ergodic scalar diffusion processes of the type
|
dX(t) = b(X(t))dt + |
(1) |
It is shown that the above diffusion model is asymptotically equivalent to the Gaussian white noise model given by the observation of
|
dZ(x) = b(x) |
(2) |
Nonparametric estimation for diffusion processes based on low-frequency data is an intricate problem and had first been considered in [12] for compact state spaces. In [52], this approach has been generalized to diffusion processes with natural boundary conditions on the state space IR. This extension poses many new difficulties: On the probabilistic side, the corresponding infinitesimal generator is usually not compact anymore and its eigenfunctions are unbounded, while statistically the highly degenerate observation design causes a heteroskedastic noise structure.
Using warped wavelet bases and imposing conditions on the underlying Dirichlet form, some of the difficulties can be overcome and mathematical efficiency results are obtained. The procedure is based on projection estimators for the invariant density and the Markov transition operator and on spectral decomposition results. Numerical simulation results, implementing the method with an adaptive wavelet thresholding approach, support the feasibility of this estimation procedure.
Inverse problems appear naturally in all areas of quantitative science, cf. the calibration problem described in the applied finance section. A statistical formulation is needed when modeling the error stochastically or when solving statistical inference problems for stochastic processes. An instance of the latter is the estimation of the delay length r in the affine stochastic differential equation
The problem of an error in the operator, e.g., due to uncertainty
about certain parameter values or due to numerical approximation
errors, has been considered more fundamentally in [15].
The problem of recovering f ![]() L2 from the
observation
L2 from the
observation
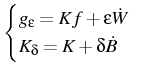
SIMEX was introduced in [7, 59] as a simulation-type estimator in errors-in-variables models. The idea of the SIMEX procedure is to compensate for the effect of the measurement errors while still using naive regression estimators. In [47, 48], a symmetrized version of this estimator is defined. Now [49] establishes some results relating these two simulation-extrapolation-type estimators to well-known consistent estimators like the total least squares estimator (TLS) and the moment estimator (MME) in the context of errors-in-variables models. We further introduce an adaptive SIMEX (ASIMEX). The main result of this paper is that SYMEX, ASIMEX are equivalent to total least squares. Additionally, we see that SIMEX is equivalent to the moment estimator.
Easy-to-understand graphical output of cluster analysis would be appreciated in the reality of a high-dimensional setting. To supply this need, new graphical outputs of hierarchical clustering are under development. Hierarchical cluster analysis is a well-known method of stepwise data compression. As a result one gets a dendrogram, that is, a special binary tree with a distinguished root and with all the data points (observations) at its leaves. Unfortunately, both the real or potential order of the objects and the potential quantitative locations of the objects are not reflected in the dendrogram. Often, neighboring objects in the dendrogram are quite distinct from one another in the reality of a heterogeneous, high-dimensional setting. Therefore, the reading of conventional dendrograms as well as their interpretation becomes difficult and it is often confusing. In [35], some dendrogram drawing and reordering techniques are recommended that reflect the total order in the one-dimensional case (univariate case) and, in the multivariate case, an order that corresponds approximately to a total order in some degree. The result, a so-called ordered dendrogram, is recommended because it makes the interpretation of hierarchical structures much easier.
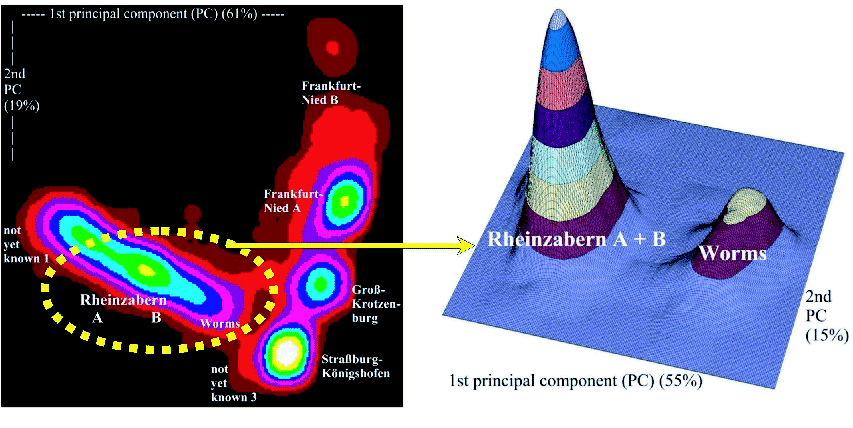
Another focus is on the development of stable clustering techniques. Usually, a (global) cluster analysis model is applied first in order to find homogeneous subsets in data. As a result, ten or more clusters are detected in a heterogeneous data set. Often subsequent (or iterative) local cluster analyses perform better. This can be confirmed by using validation techniques [36]. By doing so, both the appropriate number of clusters can be validated and the stability of each cluster can be assessed. Figure 3 shows a successful application in archeometry. At the left-hand side, the overall cluster analysis result is presented based on the first two principal components. The clusters correspond to the high-density areas of the nonparametric bivariate density estimation. Several cuts of the density at different levels are shown. At the left-hand side of the figure, the local adaptive cluster analysis result corresponds to the two well-separated peaks of the bivariate density surface.
References:
|
|
|
[Contents] | [Index] |